
PerlやPythonでWebスクレイピングをやったことはあったのですが、今回PHPで初めて使ってみたので、使った内容を備忘しておこうと思います٩( ‘ω’ )و
DOMDocumentクラスのインスタンス生成
最初にDOMDocumentクラスのインスタンスを生成して、
スクレイプしたいWebのhtmlを読み込ませます
試しに当ブログの最初の記事をスクレイプしようと思います
$url = 'http://memorandum-plus.com/2018/01/15/sql%E3%81%AE%E5%9F%BA%E6%9C%AC%EF%BC%88update%E3%80%81insert%E3%80%81delete%EF%BC%89/'; $html = file_get_contents($url); $dom = new DOMDocument; //インスタンス生成 @$dom->loadHTML($html); //読み込み
読み込みの際は、対象のWebサイトのhtml構造にちょっとでもエラーがあるとwarningがでてしまうので@でエラーを抑制します
文字化けが発生する場合
HTML5のcharset記述に対応していないため、対象のWebサイト次第では文字化けが発生する場合があります
| 記述 | 文字化け |
|---|---|
| <meta charset=”UTF-8″> | 文字化けしちゃう |
| <meta http-equiv=”Content-Type” content=”text/html; charset=UTF-8″> |
大丈夫 |
そんな時は無理やり置換するとうまくいきます
$html = str_replace('<meta charset="UTF-8">',
'<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">',
$html
);
$dom = new DOMDocument;
@$dom->loadHTML($html);
以下のようにマルチバイト文字に変換してうまくいく場合もありますが、
なんか出来ないときもあるので、どちらかで試してみてください
$html = mb_convert_encoding($html, "HTML-ENTITIES", "UTF-8"); $dom = new DOMDocument; @$dom->loadHTML($html);
XPathによる解析
DOMXPathクラスを使って、XPathによる構造の解析ができます
DOMXPath::query()メソッドを使います
とりあえず例を見てみましょう
$xpath = new DOMXPath($dom); //インスタンス生成
foreach($xpath->query('//div[@class="entry-content"]/h2') as $node){
echo $node->nodeValue;
echo '<br>';
}
実行結果
UPDATE INSERT DELETE
DOMXPathのインスタンス生成
1行目でまずインスタンスを生成します
$xpath = new DOMXPath($dom); //インスタンス生成
query()メソッドによる探索
2行目でquery()メソッドを使って、htmlの構造から取りたい部分を探索します
foreach($xpath->query('//div[@class="entry-content"]/h2') as $node){
引数の部分で構造を指定します
ここはちょっと細かく説明しますね(*`・ω・)ゞ
'//div'
query()メソッドの引数に↑を入れるとhtml中の全てのdivタグが探せます
//はhtmlのルートノードから全てを探索する時に指定します
'//div[@class="entry-content"]'
[]の中でさらに条件を絞り込むことが出来ます
@をつけると属性を指定でき、↑ではclass名がentry-contentのdivタグを全て探します
また、
'//@class'
のように指定すると、class名がつけられているタグ全て探します
最終的に今回の例では、
'//div[@class="entry-content"]/h2'
を指定していて、
class名がentry-contentのdivタグの1階層下の子ノードの中からh2タグを探しに行きます
1階層ではなく、その下の階層全てを探索したい場合は
'//div[@class="entry-content"]//h2'
のように指定します。
DOMNodeListクラスのインスタンス生成
query()メソッドからDOMNodeListクラスのインスタンスが生成されます
例えば以下のように。
$dom_node_list = $xpath->query('//div[@class="entry-content"]/h2');
↑の例では、query()メソッドで探索されたノードのリストが$dom_node_listに入っています
DOMNodeListクラスのインスタンスはDOMNodeList::item()メソッドを使って、
中のDOMElementクラスのインスタンスを取り出せます
例えばこんな感じで↓
//item()の引数にはリストのインデックス番号を指定 $dom_element = $dom_node_list->item(0);
そろそろコイツ何言ってんだ(; ・`д・´)?
って感じになりそうですが、つまりは
↑の操作によって、query()メソッドで探索して見つけた最初の要素を得られます
試しにvar_dump()を使って、$dom_elementを見てみましょう
//query()メソッドで探索した結果から、DOMNodeList生成する
$dom_node_list = $xpath->query('//div[@class="entry-content"]/h2');
//item()の引数にはリストのインデックス番号を指定
//インデックスの最初は0
$dom_element = $dom_node_list->item(0);
var_dump($dom_element);
実行結果
object(DOMElement)#3 (18) {
["tagName"]=>
string(2) "h2"
["schemaTypeInfo"]=>
NULL
["nodeName"]=>
string(2) "h2"
["nodeValue"]=>
string(6) "UPDATE"
["nodeType"]=>
int(1)
["parentNode"]=>
string(22) "(object value omitted)"
["childNodes"]=>
string(22) "(object value omitted)"
["firstChild"]=>
string(22) "(object value omitted)"
["lastChild"]=>
string(22) "(object value omitted)"
["previousSibling"]=>
string(22) "(object value omitted)"
["nextSibling"]=>
string(22) "(object value omitted)"
["attributes"]=>
string(22) "(object value omitted)"
["ownerDocument"]=>
string(22) "(object value omitted)"
["namespaceURI"]=>
NULL
["prefix"]=>
string(0) ""
["localName"]=>
string(2) "h2"
["baseURI"]=>
NULL
["textContent"]=>
string(6) "UPDATE"
}
注目していただきたいところは
[“nodeValue”]=>
string(6) “UPDATE”
のところですね
実際のスクレイプ先のhtmlと見比べてみましょう
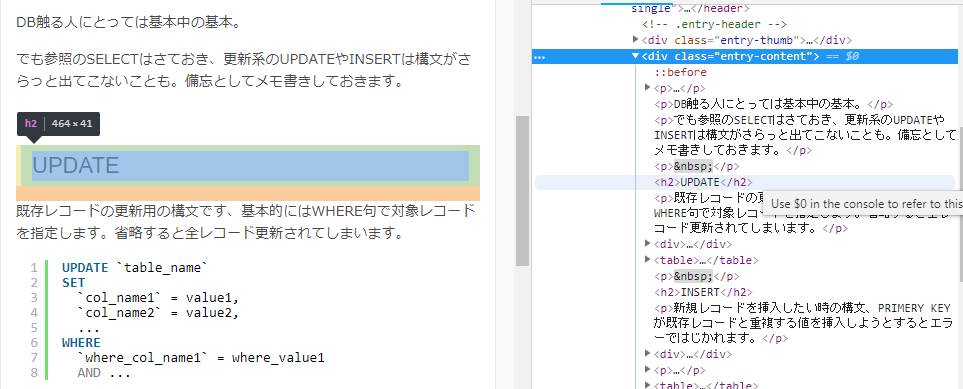
スクレイプ先のブログ記事で、div class=”entry-content”は記事の本文全体です
さらにその中で、h2のタグが最初に出てくるところは、UPDATEですね!
nodeValueプロパティには発見したタグ要素の内側のテキストがstringで入っています
textContentプロパティにも同じように入っていますが、
ここの違いはちょっとすいません、あんましわかってないです( ´・ω・`)
テキスト文字列は
$dom_element->nodeValue;
で取り出せます
foreachによる反復処理
すいません、ちょっと最初のコードの例からそれてきてしまいましたが、
戻って説明します
$xpath = new DOMXPath($dom); //インスタンス生成
foreach($xpath->query('//div[@class="entry-content"]/h2') as $node){
echo $node->nodeValue;
echo '<br>';
}
↑のforeachはhtml中からquery()メソッドの引数で指定されたノードを探索して、
発見するたびに$nodeにDOMElementをぶち込みます
今回のスクレイプ先の記事では本文中にh2タグが3回出てきています
echoでh2タグの内容を出力しているので、実行結果として以下のようになります
実行結果
UPDATE INSERT DELETE
最初にDOMNodeListクラスの方で説明しましたが、
DOMNodeList::lengthプロパティで、発見したノード数が分かるので、
foreachではなく、以下のやり方で同じように反復させることも可能です
$dom_node_list = $xpath->query('//div[@class="entry-content"]/h2');
for($i=0; $i<$dom_node_list->length; $i++){
echo $dom_node_list->item($i)->nodeValue;
echo '<br>';
}
いかがでしょうか
また、nextSiblingプロパティで弟要素を取得したり、childNodesプロパティで子要素を取得したりも出来るのですが、長くなってきたので一旦このあたりで今回は終わろうと思います~|д・´)
